In the era of streaming services and endless entertainment options, the ability to deliver personalized movie recommendations is key to enhancing user experience and engagement. Leveraging the power of machine learning, we embark on a journey to develop a sophisticated movie recommendation system capable of suggesting relevant films based on user preferences and viewing history. In this article, we explore the methodologies, algorithms, and potential applications of machine learning in movie recommendation, offering insights into the dynamic world of personalized content discovery.
- Data Collection and Preprocessing:Our journey begins with the acquisition of movie-related data encompassing information on titles, genres, ratings, user preferences, and viewing histories. Through meticulous preprocessing steps such as data cleaning, normalization, and feature engineering, we ensure the quality and relevance of the data for model training and analysis.
- Collaborative Filtering and Content-Based Filtering:Next, we explore two popular approaches to movie recommendation: collaborative filtering and content-based filtering. Collaborative filtering leverages user-item interactions to identify similar users or items and make recommendations based on their preferences. Content-based filtering, on the other hand, analyzes the characteristics of movies and users' past preferences to generate personalized recommendations.
- Model Training and Evaluation:With our data prepared and algorithms selected, we train machine learning models to learn patterns and relationships between users, movies, and their features. Models are evaluated using metrics such as precision, recall, and mean average precision to assess their performance in accurately predicting user preferences and recommending relevant movies.
- Integration and Deployment:Once trained and evaluated, our recommendation system is integrated into streaming platforms or movie databases, where it provides personalized recommendations to users based on their browsing history, ratings, and demographic information. Continuous monitoring and refinement ensure that the system remains effective and adapts to changing user preferences over time.
- Enhancing User Experience:By delivering personalized movie recommendations, our recommendation system enhances user experience, increases user engagement, and drives content discovery. Users are more likely to discover new and relevant films tailored to their tastes, leading to higher satisfaction and retention rates for streaming platforms and movie services.
Download the Data set from Kaggle Repository or from below Download.
The below code is .Python file.
# %% [markdown]
# # Movie Recommendation System
# %%
!pip install wordcloud
# %%
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from wordcloud import WordCloud
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
sns.set_style('darkgrid')
# %%
## reading dataset
df_movies = pd.read_csv(r'C:\Users\jgaur\Downloads\Gaurav 50\Data Science Project 4 - Movie Recommendation System\movies.csv')
df_rating = pd.read_csv(r'C:\Users\jgaur\Downloads\Gaurav 50\Data Science Project 4 - Movie Recommendation System\ratings.csv')
# %%
## displaying first 5 rows of movies dataset
df_movies.head()
# %%
## displaying last 5 rows of ratings dataset
df_rating.tail()
# %%
print("Movies data shape: ", df_movies.shape)
print("Ratings data shape: ", df_rating.shape)
# %%
## checking null values in movies dataset
df_movies.isnull().sum()
# %%
## checking null values in ratings dataset
df_rating.isnull().sum()
# %%
df_movies.genres.unique()
# %%
total_genres = []
for g in df_movies.genres:
g = g.split('|') ## spliting every generes from '|'
## checking if the is not present in the list
if g not in total_genres:
total_genres.append(g)
# %%
total_genres
# %%
df_movies.title.head()
# %%
df_movies.title[0][:-7]
# %%
year, title = [], []
for t in df_movies.title:
title.append(t[:-7])
year.append(t[-7:])
# %%
year[:5], title[:5]
# %%
word_cloud_genre=WordCloud(width=1500,height=800,background_color='black',min_font_size=2 ,
min_word_length=3).generate(str(total_genres))
word_cloud_title=WordCloud(width=1500,height=800,background_color='cyan',min_font_size=2 ,
min_word_length=3).generate(str(title))
# %% [markdown]
# ## Plotting Movies Genres
# %%
plt.figure(figsize=(20,10))
plt.axis('off')
plt.title('Word Cloud for Movies Genre',fontsize=30)
plt.imshow(word_cloud_genre);
# %% [markdown]
# ## Plotitng Movies Titles
# %%
plt.figure(figsize=(20,10))
plt.axis('off')
plt.title('Word Cloud for Movies Title',fontsize=30)
plt.imshow(word_cloud_title);
# %% [markdown]
# ## Merging both df_movies and df_rating dataset
# %%
final_df = pd.merge(df_rating, df_movies, how='left',on='movieId')
# %%
final_df.head()
# %%
title_rating = final_df.groupby(['title'])[['rating']].sum()
title_rating = title_rating.nlargest(10,'rating')
title_rating.head()
# %%
plt.figure(figsize=(10, 10))
plt.xticks(rotation=75);
sns.barplot(title_rating.index, title_rating['rating']);
plt.ylabel('Title');
plt.xlabel('Count');
# %%
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(df_movies['genres'])
# %%
movie_user = final_df.pivot_table(index='userId',columns='title',values='rating')
movie_user.head()
# %%
cos_similarity = linear_kernel(tfidf_matrix, tfidf_matrix)
# %%
indices=pd.Series(df_movies.index,index=df_movies['title'])
titles=df_movies['title']
def recom_sys(title):
idx = indices[title]
similarity_scores = list(enumerate(cos_similarity[idx]))
similarity_scores = sorted(similarity_scores, key=lambda x: x[1], reverse=True)
similarity_scores = similarity_scores[1:21]
movie_indices = [i[0] for i in similarity_scores]
return titles.iloc[movie_indices]
# %%
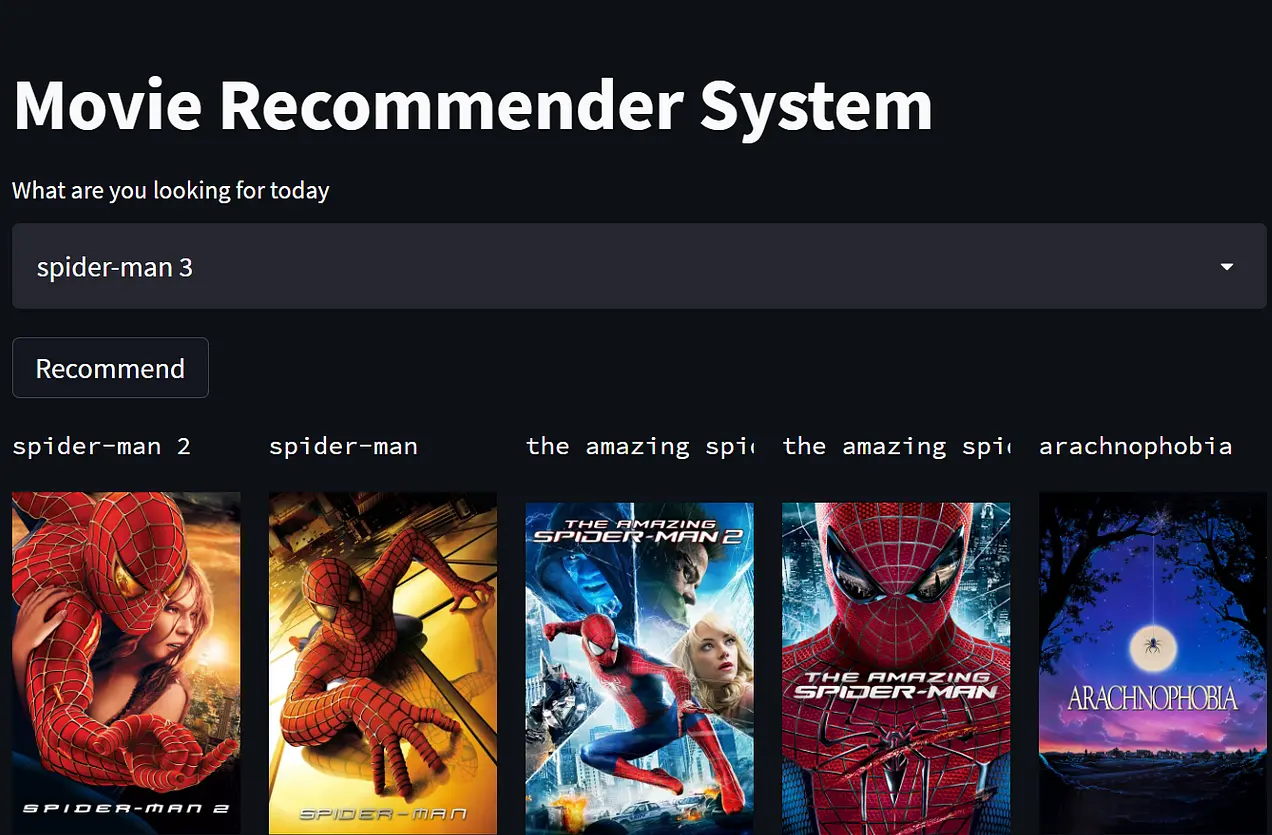
recom_sys('Grumpier Old Men (1995)')
# %%
titles
# %%Conclusion
In conclusion, the application of machine learning in movie recommendation offers exciting opportunities to revolutionize the way users discover and consume content. By harnessing the power of data-driven insights and advanced algorithms, we can develop recommendation systems that deliver personalized movie recommendations, enriching the entertainment experience for audiences worldwide.
"Stay tuned for future data science projects that will turbocharge your learning journey and take your skills to the next level!"